R.D. Jones, S. Heinicke
Hughes STX Corporation
D.A. Becker
Massachussettes Institute of Technology Media Laboratory
In order for us to keep track of all of this data across multiple programs and to understand it better in our role as the primary data archive center, we have constructed a multi-layered system of cataloging Metadata. As each new data item is received for archive, temporal, spatial, and spectral range information is automaticallly extracted and populated to a "summary" catalog database; more detailed information is also extracted and populated to a "program" catalog. Users can locate and obtain data using the Summary Catalog interface. Users can then use the detailed program catalogs to assist in the analysis of the data they have received.
We have constructed an easy to use interface which is based on Jason Ng's (NCSA) GSQL scripts. The GSQL scripts have been modified to permit access to the INGRES RDBMS (so far as we know, we are the first group to make this link) and the use of "on the fly" form and graphical image construction.
Projecting our experience onto the the global problem of locating data, we suggests the implementation of an international distributed database system. This SQL-based distributed server system would allow users to construct queries using standard HTML form sets and locate data at any of the participating servers aground the world.
Most of the expected new data are from the Midcourse Space Experiment (MSX) which is scheduled for launch this year. MSX is a multi-sensor platform which will obtain spectral, radiometric and image data of the Earth and the celestial backgrounds in the UV, Visible and IR regions of the spectrum. The BDC has expended great effort, in concert with the MSX Data Management organization, to ensure that the archived data will be easily accessible to users.
We have found that the a primary difficulty in being an archive center is in locating data which satisfies a user's needs. For example, if an investigator is interested in data in spectra in the extreme UV of the Eta Carina region how do we process this request? What if the investigator is interested in just one of the supported programs? What if he is interested in all of the supported programs?
The efficacy of the catalog (and thus the system as a whole) depends on how much and what sort of information is contained within it. The structure of the catalog dictates how much information should go into it while the data management system (i.e. the method for receiving and processing the data) determines how much of the information which should go in actually does.
It is useful to think in terms of the granularity of the catalog. By this we mean the level of detail which is contained for each discrete entry. A catalog with small granularity contains relatively many discrete entries each with a high level of detail associated with it, while a catalog with large granularity contains relatively fewer entries with less detail about each entry. We maintain two types of catalogs: the program catalog (small granularity) and the summary catalog (large granularity). Information about each program's data is recorded in detail in a specific program catalog. Information about data for each program at a larger granularity is recorded in the summary catalog.
We call this information about the data metadata.
By metadata we mean
information which describes the setting of the actual data product. For
example, the IR spectra of central region of the Small Magellanic Cloud is
data, but information about when the data was taken, what filter was used in
the instrument, what RA and DEC , etc., is what we call metadata. It is by
means of the metadata that we locate data for the investigator; it is to him
to use the data once located. It is therefore the metadata which fills the
catalogs.
One further distinction we make that is related to the catalog granularity is
that of dataset range vs. data product. As the number of rows in a catalog
increases, so does the query time, and as the number or programs n , each
containing individual entries m, the total number of entries in a
comprehensive database is (i=1 to n) S mi .
At sufficiently large numbers of entries per program (e.g. hundreds of
thousands) this forces the designers of the database to either
tolerate extremely long search times, or to make the granularity
larger and lose some information. We have addressed this problem by
making the discrete data entry a relatively large granule and then
recording range information rather than specific values. The summary
catalog entries thus are composed of sets of data
products--datasets--and associated ranges. The modus operandi for
locating data is thus to construct a range query and submit it to the
summary catalog. This results either in a negative answer, or a list
of datasets which satisfies his query. The investigator can order the
dataset(s) and then use the much more detailed information in the
associated program catalog to select and locate actual data products
such as scenes or spectra.
2.3 The Structure of the Metadata Catalog
The intent of this paper is not to discuss the detailed design of RDBMs, but
we will make some relevant observations. There are a number of tricks to
optimizing the processing time for queries which any good SQL programmer
should employ. These involve such things as analysis of the typical types of
queries expected, use of indices and multiple tables rather than single
tables with a large number of columns, and so-called 'sanity checks' which
return the number of potential row answers before an actual query is
committed, etc. The catalog should be designed with speed and efficiency
foremost rather than ease-of-use; construction of the optimal interface (vide
sections 3 and 4)
will shield the user from the inner workings of the catalog
database.
Interfaces have typically presented a multitude of problems. These problems take the form of a "trade-off". These include standardization vs. power and ease-of-use vs. versatility. A number of corollary problems typically arise when trade-offs are settled by making certain choices. The major problems we have noted are:
Another solution is to remove the interface altogether and permit direct access using SQL. Users must be SQL experts and must have access to database dictionaries, etc. for this to work. This is asking a lot of the investigator who is interested in getting his data, not in learning database query language.
We initially constructed a form which contained all possible query parameters and provided that to the user. The HTML form appeared to us to be the perfect tool for connecting users to a catalog database. It was standard across all supported hardware configurations, and it is inherently easy to use and has the potential (implementation is a different matter) for being intuitive in use. What we found, however, was that even at the high level of granularity of our summary catalog, and dealing solely with a limited number of query parameters, our form was cumbersome to use. Any thought of using this method for preparing queries for highly detailed program catalogs was unacceptable. Furthermore, a rigid form interface does not address the issue of ease of use vs. versatility. We still had to make compromises between giving the user a lot of choices and not making the task an impossible one to manage by non-SQL experts.
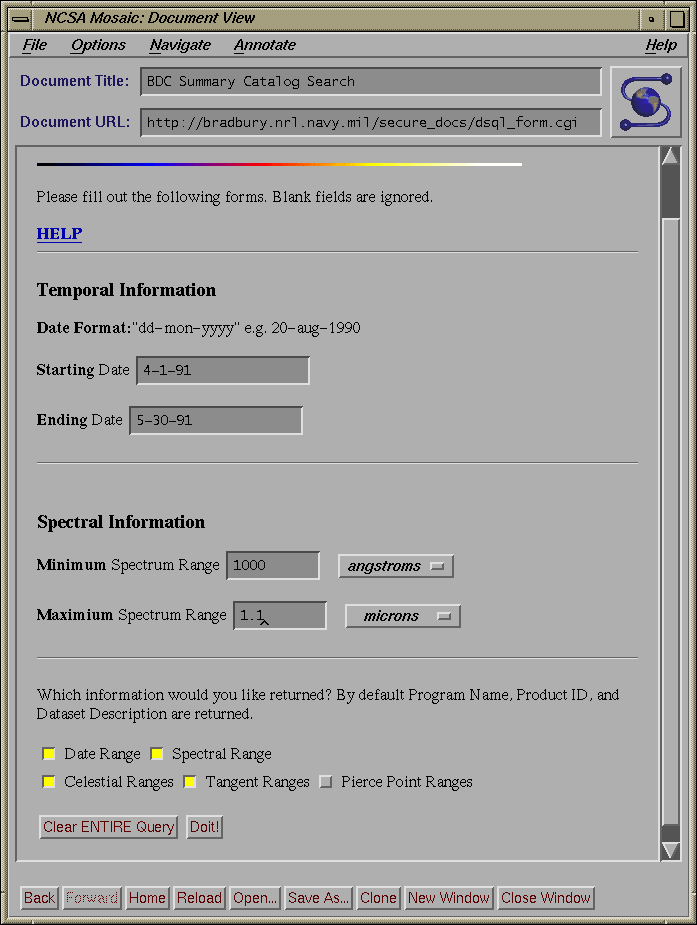
When a user first enters the summary catalog interface he will see a form that consists of 10 CHECKBOX buttons, 3 RADIO buttons, and 2 buttons for resetting and submitting. Each of the CHECKBOX buttons corresponds to a query element (i.e. time/date range, spectral range, etc..) and each of the RADIO buttons corresponds to a type of query form (i.e. standard, advanced, or editable). Once the user has selected the desired query elements and the type of query. The contents of the form are submitted using the POST method to dsql_form.cgi.
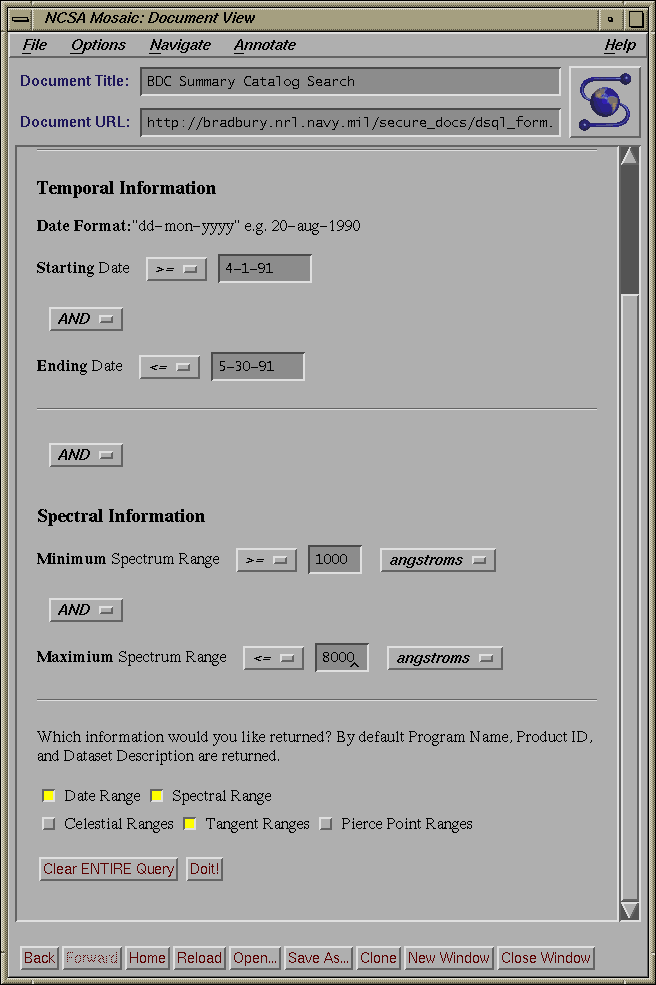
Dsql_form.cgi takes the input (passed through STDIN, as per POST method) from the initial form and builds a form that contains only those elements selected on the initial form. The form generated by dsql_form.cgi comes in two flavors. If the standard option was selected, the form only has INPUT fields for the minimum and maximum of each query element. If either the advanced or editable query type were selected, a form is generated that contains not only INPUT fields for the minimum and maximum of each query element, but also SELECT fields that contain logical operators (AND, OR) for combining the various parts of the queries and range operators ( >=,>,=,<>,<,<= ) which affect the range of the queries. Both flavors will have a MULTIPLE SELECT field if the Program Acronym element was selected. In addition at the bottom of each form, are five CHECKBOX buttons that allow the user to choose what type of information he wants returned from the query. The user can select information regarding: temporal ranges, spectral ranges, celestial ranges (i.e. RA and DEC), tangent point ranges and pierce point ranges. The contents of this form are submitted with the POST method to one of three shell scripts depending on the type of query. The shell scripts are necessary to set certain PATH information for use by INGRES.
Once the PATH information is set, the scripts call their respective programs which parse the data, build an SQL query and submit it to INGRES for processing. Each of the three programs are slightly different.
The Standard Program takes the inputs and builds a standard query. This standard query is an expert level SQL query which does two things for users. First, the query returns a maximum number of data sets which meet the given parameters. This is achieved by building the query so that the data set's minimum value for a given parameter (e.g. the data set's minimum RA) has to be less than the maximum value for the parameter provided by the user and the data set's maximum value for a given parameter (e.g. the data set's maximum RA) has to be greater than the minimum value for the parameter provided by the user. This ensures the database returns all data sets which have values in the ranges provided by the user. Second, the query takes into account the circular nature of several of the parameters ( RA, longitude). These parameters are particularly complicated to work for two resaons:
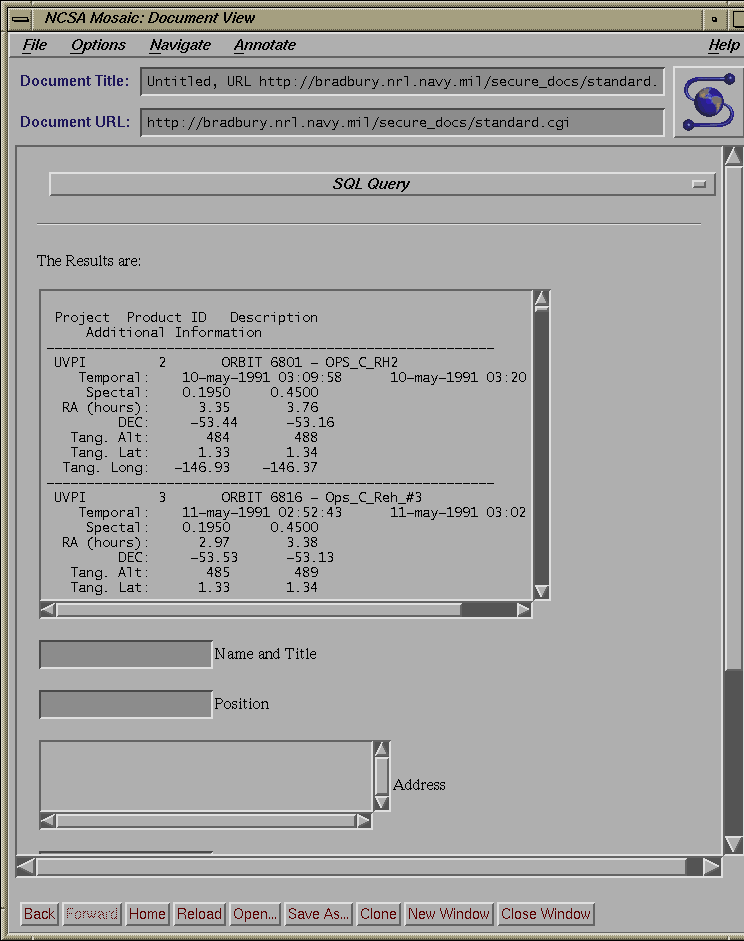
The Advanced Program and the Editable Program take the inputs and build the query as defined by the user (remember that with the advanced and editable queries, the user selects both logical and range operators). Once the queries are built they are passed to a backend written in C and embedded SQL. Before the Editable Program submits the query to INGRES, it first displays the query in a user-editable TEXT field. If the user wishes, he can modify the query before submitting it to the backend. The backend submits the query to the INGRES database, which processes it and returns both the standard results (Program Acronym, Product ID, and Dataset Description), and any additional information (Temporal Ranges, Spectral Ranges, Celestial Ranges, Tangent Point Ranges, and Pierce Point Ranges) the user requested.
The combination of this method of constructing interfaces along with intelligent design and correct population of catalog databases makes locating data by means of metadata query an easy to use and powerful tool for the user of archived data.
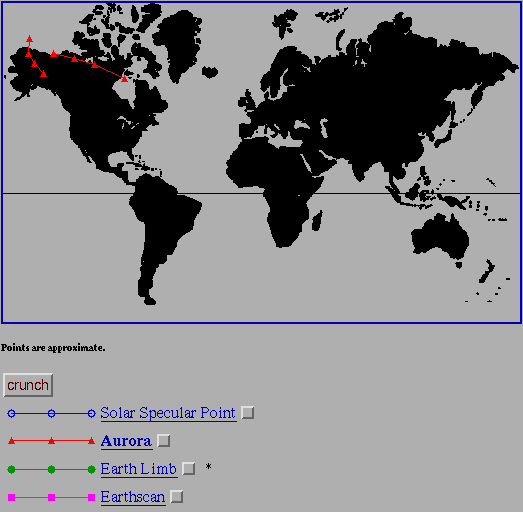
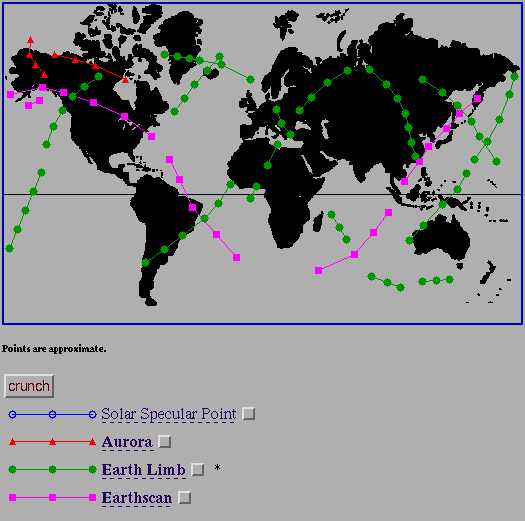
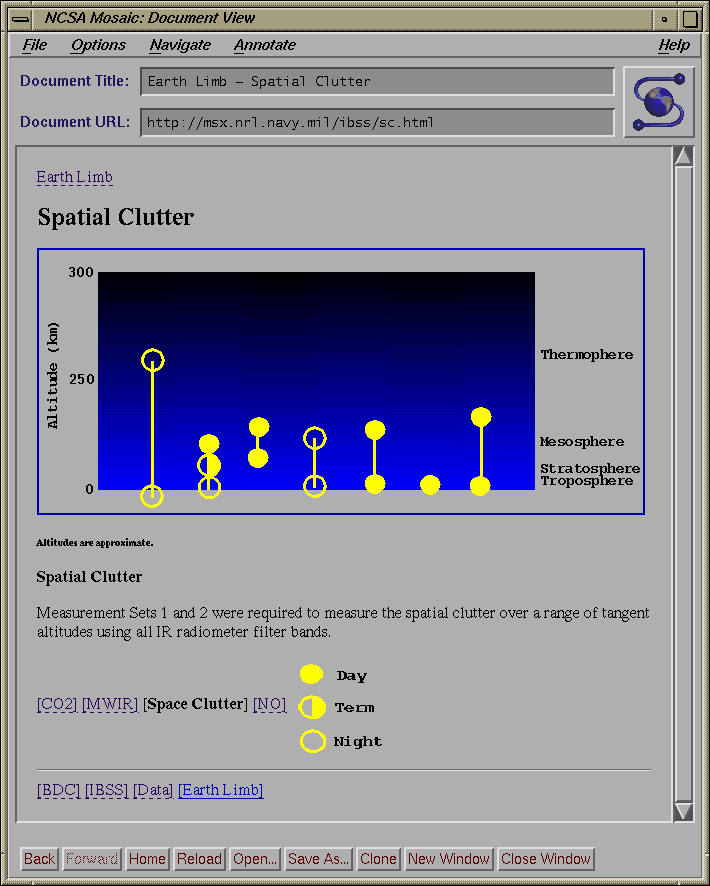
The importance of this to SQL interface is clear. An additional, and even easier to use interface can now be incorporated into the entire interface package. This must be done prudently, as not all information is necessarily displayed best graphically. Spectral ranges, for example, do not gain anything by being displayed as a rainbow, but in fact may lose some precision if actual numbers are not entered into a field. Furthermore, this interface must become part of the described methodology; i.e. an aspect of the entire interface and not an outright replacement.
The problem of locating data outside of an archive center--on the Internet--is a much larger problem. While there are a number of useful tools, such as meta-indices, for finding data, it is generally a matter of luck as to whether one can find the precise data of interest. Consider this situation: a user is looking for short-wave infrared data of southern California with a spatial resolution of 100-1000 km. How can he find this?
Typically, a user now will launch out over the WWW and poke around in likely places and try to find some information here and there which may point him in the right direction. Consider how useful the following tool would be, however: a user would connect to a standard host (much like an archie host) and fill out a dynamic Image- and forms-based HTML query. He would be able to select a discipline, and also be able to select the query parameters applicable to the discipline. He would be presented with a query form (or imagemap) based on his preliminary selections. He would then fill out the query, and the query server would then distribute the query to a world-wide web of database servers. Each of these would then process the query and return the answer to the client. He would have a list of data products which satisfied his query, and links to the products or information on ordering them along with the list.
Such a system would be a powerful tool for locating and obtaining science data on the internet. By making the functionality dynamic, it could incorporate all sorts of science disciplines and not be restricted to simple astronomy or geophysics. Query interface tools would be modular and added or modified without affecting the rest of the (parallel) tools.
Our opinion is that the easiest way to construct such a system would not be to enforce standardization, but rather to build specialized interface tools which would handle interaction between and environment of distributed, heterogeneous database servers and the query clients. Standardization would in all likelihood not work, and the system would likely fall quickly into disrepair. If we allow each data archive center to maintain its own functional database and spend our effort in creating an interface between the database and the query system, we feel that an operational system would be feasible. An example of a distributed, heterogeneous system of databases was described by Ford and Stern at the Second International World Wide Web conference in 1993. They describe a much smaller system composed of at most 20 databases, but the principal can easily be extended to an international system of hundreds of databases. We feel that such a system would be a large step in managing the oddly dual nature of information on the Internet now--an overabundance of information and a paucity of information management.