In order to be able to make calibration at a bandwidth smaller than the hardware chunks, MRTCAL is able to map the raw data block read with CFITSIO into smaller memory chunks. The main advantage is that this approach has very well defined boundaries: when the IMBFITS BACKEND table is read, it can be replaced on-the-fly with its sliced version. All the rest of the code does not have to know this happened. The downside is that the more memory chunks are defined, the more overheads they carry (e.g. description of their spectroscopic axis, calls to chunk-by-chunk subroutines, stitching, etc). Experience shows that slicing the 1400 MHz of FTS chunks into 14 chunks of 100 MHz introduces a penalty of 10% in the whole computation time (reading, slicing, calibrating, writing).
In practice, user can request the bandwidth he wishes. In order to
slice the USED channels into comparable pieces, MRTCAL will
choose the nearest bandwidth which gives an integer number of slices:
| (1) |
| (2) |
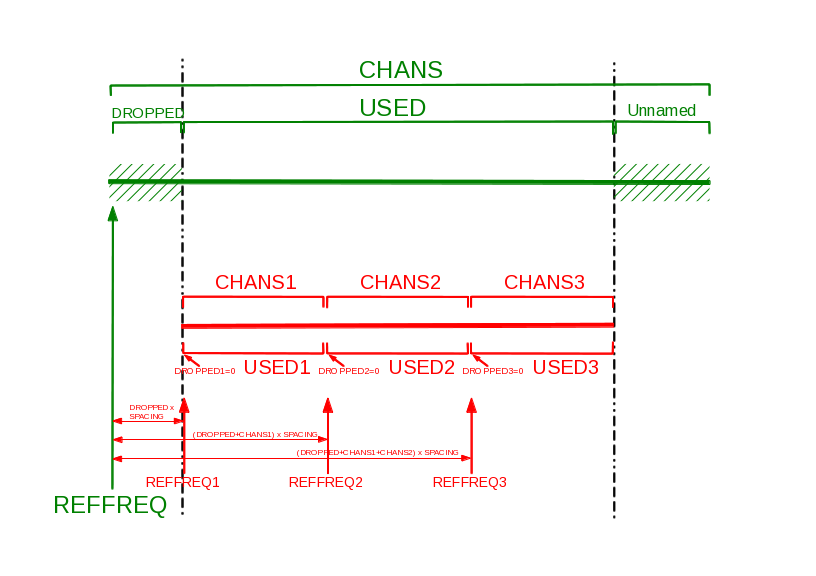
While the CHANS value (total number of channels) is often a
multiple of 2, USED channels have no special value. In
particular, it may not be a multiple of ![]() . Their relationship can be
written as:
. Their relationship can be
written as:
| (3) |
| (4) |
This gives the best channels division and a negligible difference of subchunks bandwidth.
|
ZZZ Say a word about the ``famous'' special channel with its half weight. Slicing does not have any special problem with it.