


Next: Warning
Up: Implications
Previous: New OTF data format
Contents
Almost all processing steps are available spectrum per spectrum because
this is a very powerful way to work around the limitation of your computer
RAM memory. There are two main exceptions:
- When opening a file, CLASS is buffering information (source name,
line name, telescope name, scan number, offset, etc...) on each
observations of the file to speed next find commands. This
buffer has a fixed sized to avoid code complexity. This limits the number
of observations that CLASS90 can read/write during one session. The
default maximum number of observations is currently set to
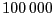 which amounts to about 5 MB of RAM memory. This number can be set to a
larger value through the
which amounts to about 5 MB of RAM memory. This number can be set to a
larger value through the CLASS_IDX_SIZE logical variable in your
$HOME/.gag.dico configuration file as it is probable that the
default value is too small with the largest maps observed today.
- In CLASS90, it is also possible to load a whole index as a single
2D array for further visualization and processing (see below). There is
no limitation on the number of dumped spectra loadable, apart from the
previous limitation and the RAM memory of your computer.
Except from the index buffer, all other CLASS90 buffers are now
dynamically allocated, in particular the buffer R & T containing the
spectra data. This means that the number of channels of a spectrum is now
unlimited which is a useful feature for line surveys.
Next: Warning
Up: Implications
Previous: New OTF data format
Contents
Gildas manager
2014-07-01