It should be noticed that the transformation
of FITS to VOTable is meant to be reversible:
any FITS table can be converted to a VOTable without loss of
information and the resulting VOTable can be converted back to a
FITS table also without loss of information.
However, it is
possible to create new VOTables which cannot be converted to FITS
tables without loss of information.
3 The VOTable Document Structure
The overall VOTable document structure is described and controlled
by its XML Schema
referenced at its top. This schema actually represents the VOTable definition, which means
that documents claiming to represent VOTables should pass through
W3C XML Schema validators without error.
An illustration of the XML Schema is given in section 7.
An example is used here to illustrate the components of a VOTable document
described in the following sections.
Basically,
a VOTable document consists of a single all-containing element
called VOTABLE,
which contains descriptive elements (DESCRIPTION,
DEFINITIONS, INFO),
followed by one or more RESOURCE elements.
Each Resource element contains one or more TABLE elements,
and possibly other RESOURCE elements.
The TABLE element, the actual heart of VOTable, contains
a description of the columns and parameters
(described in the next section)
followed by the data values
(described in the following section).
3.1 Example
This simple example of a VOTable document lists 3 galaxies with their
velocity with its error, and the estimated distance.
<?xml version="1.0"?>
<VOTABLE version="1.1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://vizier.u-strasbg.fr/xml/VOTable.xsd">
<DEFINITIONS>
<COOSYS ID="J2000" equinox="2000." epoch="2000." system="eq_FK5"/>
</DEFINITIONS>
<RESOURCE name="myFavouriteGalaxies">
<TABLE name="results">
<DESCRIPTION>Velocities and Distance estimations</DESCRIPTION>
<PARAM name="Epoch" datatype="float" ucd="TIME_EPOCH"
value="2003.875/">
<FIELD name="RA" ID="col1" ucd="POS_EQ_RA_MAIN" ref="J2000" datatype="float"
width="6" precision="2" unit="deg"/>
<FIELD name="Dec" ID="col2" "POS_EQ_DEC_MAIN" ref="J2000" datatype="float"
width="6" precision="2" unit="deg"/>
<FIELD name="Name" ID="col3" ucd="ID_MAIN" datatype="char" arraysize="8*"/>
<FIELD name="RVel" ID="col4" ucd="VELOC_HC" datatype="int"
width="5" unit="km/s"/>
<FIELD name="e_RVel" ID="col5" ucd="ERROR" datatype="int"
width="3" unit="km/s"/>
<FIELD name="R" ID="col6" ucd="PHYS_DISTANCE_TRUE" datatype="float"
width="4" precision="1" unit="Mpc">
<DESCRIPTION>Distance of Galaxy, assuming H=75km/s/Mpc</DESCRIPTION>
</FIELD>
<DATA>
<TABLEDATA>
<TR>
<TD>010.68</TD><TD>+41.27</TD><TD>N 224</TD><TD>-297</TD><TD>5</TD><TD>0.7</TD>
</TR>
<TR>
<TD>287.43</TD><TD>-63.85</TD><TD>N 6744</TD><TD>839</TD><TD>6</TD><TD>10.4</TD>
</TR>
<TR>
<TD>023.48</TD><TD>+30.66</TD><TD>N 598</TD><TD>-182</TD><TD>3</TD><TD>0.7</TD>
</TR>
</TABLEDATA>
</DATA>
</TABLE>
</RESOURCE>
</VOTABLE>
|
This simple VOTable document shows a single RESOURCE made of a single TABLE;
the table is made of 6 columns, each described by a FIELD, and has
one additional PARAM parameter (the Epoch). The actual rows are
listed in the DATA part of the table, here in XML format
(introduced by TABLEDATA); each cell is marked by the TD element,
and follow the same order as their FIELD description:
RA, Dec, Name, RVel, e_RVel, R.
3.2 ID and name attributes
Most of the elements defined by VOTable may or have to bear names,
like a RESOURCE, a TABLE, a PARAM or a FIELD.
Naming an element is generally possible by means of one of or
both ID and name attributes.
ID and name attributes have a different role in
VOTable: the ID is meant as a unique identifier of an element
seen as a VOTable component,
while the name is meant for presentation purposes, and need
not to be unique throughout the VOTable document.
The ID attribute is therefore required in the elements which have to be referenced,
but in principle any element may have an ID attribute.
According to the XML standard, the attribute ID
is a string beginning with a letter or underscore (_),
followed by a sequence of letters, digits, or any of the
punctuation characters . (dot), - (dash), _ (underscore),
or : (colon).
In summary,
the ID is different from the name
attribute in that (a) the ID attribute is made from a restricted character
set, and must be unique throughout a VOTable document
whereas names are standard XML attributes and need not be unique;
and (b) there should be support in the parsing
software to look up references and extract the relevant element with
matching ID.
3.3 DEFINITIONS element
This element may contain a definition of a coordinate system,
stored in a COOSYS
element. The COOSYS element
provides attributes for equinox and epoch, as well as a
specification of the celestial coordinate system.
The COOSYS element being the only astronomy specific part
of VOTable, it may be deprecated in the future,
as it is expected that a more formal structuring of the coordinate system
will be designed, which would encompass conventions used in space science
or solar physics. Its current definition is given below.
The DEFINITIONS element may also include one or more PARAM
elements (section 4)
that may contain user-specific data. Each of these may have
an ID attribute, that can be referenced with the ref attribute
of other elements.
The COOSYS element
This element defines a celestial coordinate system, to which the
components of a position on the celestial sphere refer.
It has an ID attribute — required if the
COOSYS element has to be referred via the ref attribute
of the position components, which is generally the case —
a system attribute which specifies the coordinate system
among "ICRS", "eq_FK5", "eq_FK4", "ecl_FK4",
"ecl_FK5", "galactic", "supergalactic",
"barycentric", "geo_app" and a user-defined "xy"
value. equinox is the parameter required to fix the
equatorial or ecliptic systems (as e.g. "J2000" as
the default "eq_FK5" or "B1950" as the default
"eq_FK4"), and epoch specifies the epoch of the positions
if necessary.
As mentioned above, the COOSYS may be deprecated in the future
in favor of a more generic way of describing the conventions used to define
the positions.
3.4 RESOURCE element
A VOTable document contains one or more RESOURCE
elements, each of these providing a description and the
data values of some logically independent data structure.
Each RESOURCE may include the descriptive elements DESCRIPTION,
INFO, COOSYS and PARAM;
it may also contain LINK
elements to provide URL-type pointers that give further information.
The main component of a RESOURCE is typically one or more TABLE
elements – in other terms a RESOURCE is basically a set
of related tables. The RESOURCE is recursive (it can contain other
RESOURCE elements), which means that the set of tables making up
a RESOURCE may become a complex structure.
A RESOURCE may have one or both of the name or ID
attributes (see above); it may also be qualified by
type="meta", meaning that the resource is descriptive
only (does not contain any actual data in any of its sub-elements).
3.5 LINK element
The LINK element is to provide pointers to other documents
or data servers on the Internet through a URL. In VOTable, the LINK
element may be part of a RESOURCE,
TABLE, GROUP or FIELD elements. The href
attribute of the LINK element can comprise any arbitrary protocol,
for example "http://server/file" or "bizarre://server/file".
VOTable parsers are not required to understand arbitrary protocols,
but are required to understand the following three common protocols:
"file:", "http:" and "ftp:".
The gref
attribute is meant for a higher-level protocol of some type, perhaps
a logical name for a data resource, perhaps a GLU reference [5].
In the Astrores format, from which VOTable is derived,
there is additional semantics for the LINK
element; the href attribute is used as a template for creating
URL's. This behavior is explained in Appendix A, and it represents
a possible extension of VOTable.
In addition to the referencing href and gref attributes
and to the naming name and ID attributes
(see name and ID), the LINK element
may announce the mime type of the data it references
with a content-type attribute (e.g. content-type="image/fits"),
and specify the role of the link by a content-role attribute
(e.g. content-role="doc" for an access to a documentation).
3.6 TABLE element
The TABLE element represents the basic data structure in VOTable;
it is made of a description of the table structure (the metadata)
essentially in the form of PARAM and FIELD elements
(detailed in the next section),
followed by the values of the described fields in a DATA
element (detailed in the section below).
The TABLE element is always contained in a RESOURCE element:
in other terms
any TABLE element has a single father made of the
RESOURCE element
in which the table is embedded.
The TABLE element contains
a DESCRIPTION element for descriptive remarks, followed
by a mixed collection of PARAM, FIELD or GROUP elements
which describe a parameter (constant column), a field (column) or a group of
columns respectively. PARAM and FIELD elements are detailed in
the next section, and the GROUP element
is presented in the following section.
Furthermore the TABLE element may contain LINK elements
that provide URL-type pointers, exactly like the LINK elements
existing within a RESOURCE element (see above).
The last element included in a TABLE is the optional DATA
element (see below): a table without any
actual data is quite valid, and is typically used to supply a complete
description of an existing resource e.g. for query purposes.
The TABLE element may have the naming attributes name and/or
ID (see name and ID conventions). A TABLE
may also have a ref attribute referencing the ID of another
table previously described, which is interpreted as
defining a table having a structure identical to the one referenced:
this facility avoids a repetition of the definition of tables which
may be present many times in a VOTable document.
4 FIELDs and PARAMeters
The atoms of the table structure are represented by FIELD and
PARAM elements, where FIELD represents the description
of an actual table column, while PARAM supplies a value
which remains constant over the whole table, like the Epoch
in the example. A PARAM may therefore be
viewed as a FIELD which keeps a constant value over all
the rows of a table, and the only difference between the two elements
is the existence of a value attribute in a PARAM
which does not exist in a FIELD.
A FIELD or PARAM element may have several sub-elements,
including the informational DESCRIPTION
and LINK elements; it may also include a VALUES element
that can express limits and ranges of the values that the
corresponding cell can contain, such as minimum (MIN),
maximum (MAX), or
enumeration of possible values (OPTION).
4.1 FIELD attributes
The valid attributes of a FIELD or PARAM are:
- the name and/or ID. The ID attribute is required
if the field has to be referenced (see
the generic ID rule).
It may help to include the ordinal number of
the column in the table in the value of the ID attribute
as e.g. ID="col3" when a single table is involved:
the connection to the
corresponding column would become
more obvious, especially in the FITS data serialization
which uses the ordinal column number in the keywords containing
the metadata related to that column.
- the datatype, which expresses the nature of the data
that is described as one of the permitted primitives
(see primitivestable above and their exact meaning
in section 7).
This attribute determines
how data are read and stored internally;
it is required, except when the ref attributes exists
in which case the FIELD is just referenced
(see the GROUP definitions)
- the arraysize attribute exists when
the corresponding table cell contains more than one of the specified
datatype, as explained above.
Note that strings are are not a primitive type,
and have to be described as an array of characters.
- the width and precision attributes define the
numerical accuracy associated to the data (see below)
- the unit attribute specifies the units in which
the values of the corresponding column are expressed
(see below)
- the ucd attribute supplies a standardized classification
of the physical quantity expressed in the column
(see below).
- the utype attribute, introduced in VOTable 1.1, is meant
to express the role of the column in the context of an external
data model (see below).
- the ref attribute defines the field as being a reference
to a column having the referenced ID attribute. This attribute
normally exists alone: if present, it precludes the existence
of any other attribute except a utype attribute,
and a value attribute for PARAM elements.
- The type attribute is not part of this standard,
but is reserved for future extensions.
In Astrores it was used to
express some pecularities of the column in the table
as type="hidden" (see link substitutions)
and type="no_query"
(see Query Extension);
an additional type="location" value is proposed
to express columns containing parts of URIs
(see fields as pointers).
The type is not part of this standard,
but is reserved for future extensions.
In addition, in the PARAM element only:
- the value attribute which exists only in the PARAM
element; this attribute is moreover required, even
when the PARAM contains the ref attribute.
4.2 Numerical Accuracy
The VOTable format is meant for transferring, storing, and
processing tabular data, and is not intended for presentation
purposes: therefore (in contrast to Astrores) we generally avoid
giving rules on presentation, such as formatting.
Inevitably however some at least of the data will have to be presented –
either as actual tables, or in forms or graphs, etc...
Two attributes were retained for this purpose:
- the width attribute is meant as a hint to the application
about the number of characters to be used for input
or output of the quantity.
- the precision attribute is meant to express the
number of significant digits, either as a number of
decimal places (e.g. precision="F2" or equivalently
precision="2" to express 2 significant figures
after the decimal point), or as a number of significant figures
(e.g. precision="E5" indicates a relative precision
of 10–5).
The existence and presentation of the special null value of
a field (when the actual value of the field is unknown) is
another aspect of the numerical accuracy, which is part of the
VALUES sub-element (see below).
4.3 Units
The quantities in a column of the table may be expressed in
some physical unit,
which is specified by the unit
attribute of the FIELD.
The syntax of the unit string is defined in reference [3];
it is basically written as a string without blanks or spaces,
where the symbols . or * indicate a multiplication,
/ stands for the division, and no special symbol is required
for a power.
Examples are unit="m2" for m2,
unit="cm-2.s-1.keV-1" for cm–2s–1keV–1,
or unit="erg/s" for erg s–1.
The references [3] provides also the list of the valid symbols,
which is essentially restricted to the Système International
(SI) conventions, plus a few astronomical extensions concerning
units used for time, angular, distance and energy measurements.
4.4 Unified Content Descriptors
The Unified Content Descriptors (UCD) can be viewed as a
hierarchical glossary of the scientific meanings of the data
contained in the astronomical tables.
The initial version was created at CDS, but the UCD definition
is currently evolving [4].
A few typical examples taken from the original UCD design:
| "PHOT_INT-MAG_B" | Integrated total blue magnitude |
| "ORBIT_ECCENTRICITY" | Orbital eccentricity |
| "STAT_MEDIAN" | Statistics Median Value |
| "INST_QE" | Detector's Quantum Efficiency |
4.5 The utype attribute
In some contexts, it can be important that FIELDs or PARAMeters
are explicitely designed as being the parameter performing some
well-defined role in
some external data model.
For instance, it might be important for an application to know
that a given FIELD expresses the surface brightness
processed by an explicit method. None of the existing name, ID
or ucd attributes can fill this role, and
the utype (usage-specific or unique type) attribute has
been added in
VOTable 1.1 to fill this gap.
In order to avoid name collisions, the data model identification
should be introduced following the XML namespace conventions,
as utype="datamodel_identifier:role_identifier".
The mapping of "datamodel_identifier" to an xml-type attribute
is recommended, but not required.
4.6 VALUES element
The VALUES element of the FIELD
is designed to hold subsidiary information about the domain of the
data. For instance, in the example (above)
we could rewrite the RA field definition as:
<FIELD name="RA" ID="col1" ucd="POS_EQ_RA_MAIN" ref="J2000" datatype="float"
width="6" precision="2" unit="deg">
<VALUES ID="RAdomain">
<MIN value="0"/>
<MAX value="360" inclusive="no"/>
</VALUES>
</FIELD>
|
The VALUES element may contain MIN and MAX elements,
and it may contain OPTION elements.
The latter may itself contain more OPTION
elements, so that a hierarchy of keyword-values pairs can be
associated with each field.
All three MIN, MAX and OPTION sub-elements
store their value corresponding to the minimum, maximum, or ``special value''
in a value attribute. MIN and MAX elements
can have an inclusive attribute to specify whether the value
quoted belongs or not to the domain, and the OPTION element
can have a name attribute to qualify the ``special'' quoted
value.
The VALUES element may also have a null attribute
to define a non-standard value that is used to specify
``non-existent data'' – for example null="-32768".
When this value is found in the corresponding data, it is assumed that no data
exists for that table cell; the parser may choose to use this also
when unparsable data is found, and the null value will be substituted
instead.
In the TABLEDATA data representation,
the default representation of a ``null'' value is an empty column
(i.e. <TD></TD>);
for fields containing arrays, individual ``null'' elements of the array
can be specified either by the value specified in the null
attribute, or by the "NaN" or "nan" text in place of the expected
numeric value.
For the FITS and BINARY data representations,
the NaN (not-a-number)
patterns are recommended to represent floating-point ``null'' values.
The ``null'' convention is therefore only necessary for primitive types
that do not have a natural ``null'' value: long, int, short, and byte datatypes.
The scope of the domain described by the VALUES element
can be qualified by type="actual", if it is only applicable to
the data enclosed in the parent TABLE. The domain of a valid
RA in the example above has the default
type="legal" qualification.
Finally the ref attribute of a VALUES element
can be used to avoid a repetition of the domain definition,
by referring to a previously defined VALUES element
having the referenced ID attribute.
When specified, the ref attribute defines completely
the domain without any other element or attribute, as e.g.
<VALUES ref="RAdomain"/>
4.7 GROUPing FIELDs and PARAMeters
The GROUP element was added in VOTable 1.1,
to group together a set of FIELDS
which are logically correlated, like a value and its error. Each field
participating in a GROUP can be defined either physically
(the FIELD contains a datatype field), or logically
(the FIELD contains only a ref attribute referencing
a field defined in the same parent TABLE).
A physical field (i.e. a single column of the table)
may therefore participate (logically) to several groups.
A straightforward example of a group, based on the example of
above, can be to replace the definitions of columns
4 and 5 by the following:
<GROUP name="Velocity" ucd="VELOC_HC">
<DESCRIPTION>Velocity and its error</DESCRIPTION>
<FIELD name="RVel" ID="col4" ucd="VELOC_HC" datatype="float"
width="5" unit="km/s"/>
<FIELD name="e_RVel" ID="col5" ucd="ERROR" datatype="float"
width="3" unit="km/s"/>
</GROUP>
|
A logical definition of this group could alternatively be
achieved by inserting just before the DATA element the following:
<GROUP name="Velocity">
<DESCRIPTION>Velocity and its error</DESCRIPTION>
<FIELD ref="col4"/>
<FIELD ref="col5"/>
</GROUP>
|
The GROUP element can have the name, ID, ucd,
utype and ref attributes.
It can include a DESCRIPTION, and any mixture of FIELDs,
PARAMeters, and other GROUPs –
this recursive grouping enabling a definition of
arbitrary complex structures.
The possibility of adding PARAMeters in groups introduces also
a possibility of associating parameter(s) to describe accurately
the context of the data stored in the table:
for instance,
it is possible to associate the actual frequency of a radio survey with
the following declaration:
<GROUP name="Flux" ucd="VELOC_HC">
<DESCRIPTION>Flux measured at 352MHz</DESCRIPTION>
<FIELD name="Flux" ucd="PHOT_FLUX_RADIO_400M" datatype="float"
width="6" precision="1" unit="mJy"/>
<PARAM name="Freq" ucd="OBS_FREQUENCY" unit="MHz" datatype="float" value="352"/>
<FIELD name="e_Flux" ucd="ERROR" datatype="float" width="4"
precision="1" unit="mJy"/>
</GROUP>
|
Similarly, the GROUP can be used to associate several parameters
to one or several FIELDs: a filter may for instance be
characterized by the central wavelength and the FWHM of its transmission
curve; or several parameters of an instrument setup may be detailed.
5 Data Content
While the bulk of the metadata of a VOTable document is in the
FIELD elements, the data content of the table is
in a single DATA element.
The data is organized in ``reading" order, so that
the content of each row appears in the same order as the order of the
FIELD tags having a datatype attribute, with each row
having the same number of items as
there are FIELD tags having a datatype attribute.
Fields without a datatype attribute have a ref
attribute, and represent references to ``true'' columns
(see FIELD attributes).
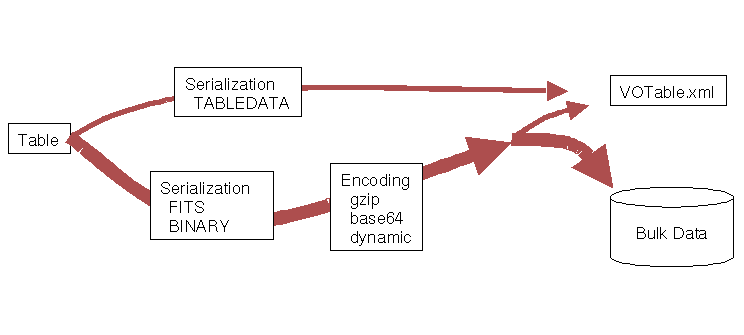 Each DATA part of the VOTable document can be viewed as
a stream coming out of a pipeline.
The abstract table is first serialized by one of several
methods, then it may be encoded for compression or other reasons. The
result may be embedded in the XML file (local data), or it may
be remote data.
Each DATA part of the VOTable document can be viewed as
a stream coming out of a pipeline.
The abstract table is first serialized by one of several
methods, then it may be encoded for compression or other reasons. The
result may be embedded in the XML file (local data), or it may
be remote data.
fig:serializationThe figure
shows how the abstract table is rendered into the
VOTable document. First the data is serialized, either
as XML, a FITS binary table, or the VOTable
Binary format. This data stream may then be encoded,
perhaps for compression or to convert binary to text. Finally, the
data stream may be put in a remote file with a URL-type pointer in
the VOTable document; or the table data may be embedded in the
VOTable.
The serialization elements and their attributes are
described in the next sections.
5.1 TABLEDATA Serialization
This element is a way to build the table in pure XML, and is the
only serialization method that does not allow an encoding or a remote
data stream. It contains TR
elements, which in turn contain TD
elements — i.e. the same conventions as the familiar HTML ones.
An example is contained in section 3.1,
surrounded by in the <TABLEDATA> and </TABLEDATA>
delimiters.
The number of TD elements should be in number equal to the
number of FIELD elements having datatype attributes
declaring the table; when there are
less TD's than expected, the corresponding values are set
to "null"s; superfluous TD's are ignored.
While this serialization has a high overhead in the number of
bytes, it has the advantage that XML tools can manipulate and present
the table data directly.
Each item in the TD
tag is passed to a reader that is implicitly defined by the datatype
attribute of the corresponding FIELD,
which attempts to read the object from it. If it reads a value that
is the same as the null
value for that field, then the cell will contain that value, and is
therefore assumed to contain no data.
Valid representations of a number in a cell, depending on their
datatype, are detailed in the complete
description of datatypes.
If a cell contains an array or complex number,
it should be encoded as multiple numbers separated by
whitespace. However in the case of character and Unicode strings, no
separators are required. Here is an example of a table with a two
rows, that has arrays in the table cells:
<TABLE>
<FIELD ID="aString" datatype="char" arraysize="10"/>
<FIELD ID="Floats" datatype="float" arraysize="3"/>
<FIELD ID="varComplex" datatype="floatComplex" arraysize="*"/>
<DATA><TABLEDATA>
<TR>
<TD>Apple</TD><TD>1.62 4.56 3.44</TD>
<TD>67 1.57 4 3.14 77 -1.57</TD>
</TR><TR>
<TD>Orange</TD><TD>2.33 4.66 9.53</TD>
<TD>39 0 46 3.14</TD>
</TR>
</TABLEDATA></DATA>
</TABLE>
|
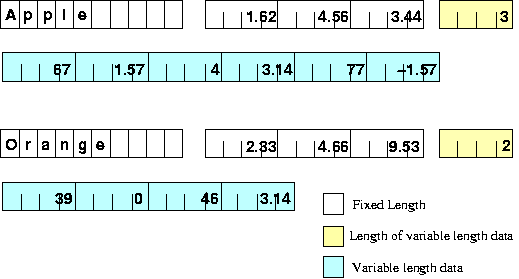
The first entry is a fixed-length array of 10 characters; since
the value being presented (Apple) has 5 characters, this
is padded with trailing blanks. The second cell is an
array of three floats.
The last cell contains a variable array of complex numbers, each complex
number being represented by its real part followed by at least a blank
and its imaginary part – hence 6 numbers for 3 complex numbers,
or 4 numbers for 2 complex numbers.
5.2 FITS Serialization
The FITS format for binary tables [2] is in widespread in astronomy,
and its structure has a major influence on the VOTable specification.
Metadata is stored in a header section, followed by the data. The
metadata is substantially equivalent to the metadata of the VOTable
format. One important difference is that VOTable does not require
specification of the number of rows in the table, an important
freedom if the table is being created dynamically from a stream.
The VOTable specification does not define the behavior of parsers
with respect to this doubling of the metadata. A parser may ignore
the FITS metadata, or it may compare it with the VOTable metadata for
consistency, or other possibilities.
The following code shows a fragment that might have been created
by a FITS-to-VOTable converter. Each FITS keyword has been converted
to a PARAM, and the data itself is remotely stored and gzipped at an
ftp site:
<RESOURCE>
<PARAM name="EPOCH" datatype="float"
value="1999.987">
Original Epoch of the coordinates
</PARAM>
<PARAM name="TELESCOP" datatype="char"
arraysize="*" value="VTel" />
<INFO name="HISTORY">
The very first Virtual Telescope observation made in 2002
</INFO>
<TABLE>
<FIELD (insert field metadata here) >
<DATA><FITS extnum="2">
<STREAM encoding="gzip" %Not for REMOTE data ?
href="ftp://archive.cacr.caltech.edu/myfile.fit.gz"/>
</FITS></DATA>
</TABLE>
</RESOURCE>
The FITS file may contain many data objects (known as extensions,
numbered from 1 up – the main header being numbered 0), and the
extnum attribute allows the VOTable to point to one of
these.
5.3 BINARY Serialization
The binary format is intended to be easy to read by parsers, so
that additional libraries are not required. It is just a sequence of
bytes, the length of each sequence corresponding to the datatype
and arraysize attributes of the FIELD
elements in the metadata. The binary format consists of a sequence of
records, with no header bytes, no alignment considerations, no block sizes.
The order of the bytes in multi-byte primitives (e.g. integers,
floating-point numbers) is Most Significant Byte first, i.e.
it follows the FITS convention.
Table cells may contain arrays of primitive types, each of which
may be of fixed or variable length. In the former case, the number of
bytes is the same for each instance of the item, as specified by the
arraysize
attribute of the FIELD.
If all the fields have a fixed arraysize,
then each record of the binary format has the same length
(the sum of arraysize
times the length in bytes of the corresponding datatype).
Variable-length arrays of primitives are preceded by a 4-byte integer
containing the number of items of the array.
The way the stream of bytes is arranged for the data of the
example in the above section is illustrated in
fig:binFigure 2.
The parser can then compute the number of bytes taken
by the variable-length array by multiplying the size and number
of the primitives.
5.4 Data Encoding
As a result of the serialization, the table has been converted to
a byte stream, either text or binary. If the TABLEDATA
serialization is used, then the table is represented as XML tags
directly embedded in the document,
document, and conventional tools can be used to encode the entire XML document.
However, VOTable also provides limited encoding of its own.
A VOTable document may point to a remote data resource that is compressed;
rather than decompressing before sending on the wire, it can be dynamically
decoded by the VOTable reader. We might also use the encoding facilities to
convert a binary file to text (through base64 encoding), so that binary
data can be used in the XML document.
In this version (1.1) of VOTable, it is not possible to encode
individual columns of the table: the whole table must be encoded in
the same way. The possibility of encoding selected table cells
is however being examined for future versions of VOTable
(see appendix below).
In order to use an encoding of the data, it must be enclosed in a
STREAM
element, whose attributes define the nature of the encoding. The
encoding
attribute is a string that should indicate to the parser how to undo
the encoding that has been applied. Parsers should understand and
interpret at the following values:
- encoding="gzip" [RFC1952]
implies that the data following has been compressed with the gzip
filter, so that gunzip or similar should be applied.
- encoding="base64" [RFC2045]
implies that the base64 filter has been applied, to convert binary
to text.
- encoding="dynamic"
implies that the data is in a remote resource (see below), and the
encoding will be delivered with the header of the data.
This occurs with the http protocol, where the MIME header indicates
the type of encoding that has been used.
The default value of the encoding attribute is the null string,
meaning that no encoding has been
applied. In future releases, we might allow more complex strings in
the encoding attribute, allowing combinations of encoding filters and
a way for the parser to find the software needed for the decoding.
5.5 Remote Data
If the encoding of the data produces text, or if the serialization
is naturally text-based, then it can be directly embedded into the
XML document, as for instance:
<DATA><BINARY>
<STREAM encoding="base64">
AAAAAj/yVZiDGSSUwFZ6ypR4yGkADwAcQV0euAAIAAJBmMzNwZWZmkGle4tBR3jVQT9ocwAA
⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅
</STREAM>
</BINARY></DATA>
However, if the data is very large, it may be preferable to keep the data
separate from the metadata. The href attribute of
the STREAM element, if present, provides the location of the data
in a URL-type syntax, for example:
<STREAM href="ftp://server.com/mydata.dat"/>
<STREAM href="ftp://server.com/mydata.dat"
expires="2004-02-29T23:59:59"/>
<STREAM href="httpg://server.com/mydata.dat"
actuate="onLoad"/>
<STREAM href="file:///usr/home/me/mydata.dat"/>
The examples are the well-known anonymous ftp, and http protocols.
"httpg" is an example of a Grid-based access to data through httpg;
"file" finally a reference to a local file.
VOTable parsers are not required to understand arbitrary protocols,
but are required to understand the three common protocols
"file:", "http:" and "ftp:".
There are further attributes of the STREAM
element that may be useful. The expires
attribute indicates the expiration time of the data:
this is useful when data are dynamically created and stored
on some staging disk where files only persist for a specified
lifetime and are then automatically deleted.
The expires
attribute expresses when a remote resource ceases to become valid,
and is expressed in Universal Time in the same way as the FITS
specification [2], itself conforming to ISO 8601 standard.
The rights
attribute expresses authentication information that may be necessary
to access the remote resource. If the VOTable document is suitably
encrypted, this attribute could be used to store a password.
The actuate
attribute is borrowed from the XML Xlink specification, expressing
when the remote link should be actuated. The default is "onRequest",
meaning that the data is only fetched when explicitly requested (like
a link on an HTML page), and the "onLoad"
value means that data should be fetched as soon as possible (like an
embedded image on an HTML page).
6 Definitions of Primitive Datatypes
This section describes the primitives summarized in
primitivesthe table of primitives
and their representations in the BINARY
and in the TABLEDATA serializations (see above).
In the following, the term ``hexadigit'' designates the ASCII numbers
"0" to "9", or the ASCII lower- or upper-case letters
"a" to "f" (i.e. a digit in an hexadecimal representation
of a number).
- Logical If the value of the datatype
attribute specifies data type "boolean",
the contents of the field shall consist in the BINARY serialization of
ASCII "T", "t", or "1" indicating true,
ASCII "F", "f", or "0" indicating false;
the ``null'' value is indicated by an sacii NULL (hexadecimal 00),
a space (hexadecimal 20)
or a question mark "?" (hexadecimal 3F).
The acceptable representations in the TABLEDATA serialization
include in addition any capitalisation variation of the
strings "true" and "false" (e.g. "tRUe" or "FalsE");
the default representation of a null value is an empty cell
(see VALUES definitions above)
- Bit Array If the value of the datatype
attribute specifies data type "bit",
the contents of the field in the BINARY serialization shall consist of
a sequence of bits starting with the most significant bit; the bits
following shall be in order of decreasing significance, ending with
the least significant bit. A bit field shall be composed of the
smallest number of bytes that can accommodate the number of elements
in the field. Padding bits shall be 0.
The representation of a bit array in the TABLEDATA serialization
is made by a sequence of ASCII "0" and "1" characters.
- Byte If the value of the datatype
attribute specifies data type "unsignedByte",
the field shall contain in the BINARY serialization a byte
(8-bits) representing a number in the
range 0 to 255.
In the case of an array of bytes (arraysize="*"),
also known as a ``blob", the bytes are stored consecutively.
The representation of a Byte in the TABLEDATA serialization
can be its decimal representation (a number between 0 and 255)
or its hexadecimal representation when starting by 0x and
followed by one or two hexadigits,
(e.g. 0xff), separated by at least one space from the next one
in the case of an array of bytes.
No default null value exists; if necessary one
has to be defined via the null attribute of the VALUES element
(section 4.6).
- Character if the value of the datatype
attribute specifies data type "char",
the field shall contain in the BINARY serialization an ASCII
(7-bit) character.
The arraysize attribute
indicates a character string composed of ASCII text.
The BINARY serialization follows the
FITS rules for character strings,
and a character string may therefore be terminated by an ASCII
NULL (hexadecimal code 00)
before the length specified in the arraysize attribute:
in this case characters after the first ASCII NULL are not defined;
and a string having the number of characters identical to
the arraysize value is not NULL terminated.
Characters should be represented in the TABLEDATA serialization
using the normal rules for encoding XML text:
the ampersand (&) can be written & (symbolic representation)
or & (decimal representation) or
& (hexadecimal representation); the less-than (<) and greater-then (>) symbols should be coded < and >
or < and > and a blank which would be interpreted
by XML as whitespace (e.g. several consecutive blanks)
should be coded or  .
- Unicode Character If the value of the datatype
attribute specifies data type "unicodeChar",
the field shall contain a Unicode character
The arraysize attribute
indicates a string composed of Unicode text —
which enables representation of text in many non-Latin alphabets.
Each Unicode character is represented in the BINARY serialization by
two bytes, using the big-endian UCS-2 encoding (ISO-10646-UCS-2).
The representation of a Unicode character in the TABLEDATA serialization
follows the XML specifications,
and e.g. the Cyrillic uppercase ``Ya'' can be written
Я in UTF-8.
- 16-Bit Integer If the value of the datatype
attribute specifies datatype "short",
the data in the BINARY serialization shall consist of
big-endian twos-complement signed 16-bit integers
(the most significant byte first).
The representation of a Short Integer in the TABLEDATA serialization
is either its decimal representation between -32768 and 32767
made of an optional - or + sign followed by digits,
or its hexadecimal representation when starting by 0x
and followed by 1 to 4 hexadigits.
No default null value exists; if necessary one
has to be defined via the null attribute of the VALUES element
(section 4.6).
- 32-Bit Integer If the value of the datatype
attribute specifies datatype "int",
the data in the BINARY serialization shall consist of
big-endian twos-complement signed 32-bit
integer — contained in four bytes, with the most significant first,
and subsequent bytes in order of decreasing significance.
The representation of an Integer in the TABLEDATA serialization
is either its decimal representation between -2147483648 and 2147483647
made of an optional - or + sign followed by digits,
or its hexadecimal representation when starting by 0x
and followed by 1 to 8 hexadigits;
No default null value exists; if necessary one
has to be defined via the null attribute of the VALUES element
(section 4.6).
- 64-Bit Integer If the value of the datatype
attribute specifies datatype "long",
the data in the BINARY serialization shall consist of
big-endian twos-complement signed 64-bit integers
— contained in eight bytes, with the most significant byte first,
and subsequent bytes in order of decreasing significance.
The representation of a Long Integer in the TABLEDATA serialization
is either its decimal representation between -9223372036854775808
and 9223372036854775807
made of an optional - or + sign followed by digits,
or its hexadecimal representation when starting by 0x
and followed by 1 to 16 hexadigits;
No default null value exists; if necessary one
has to be defined via the null attribute of the VALUES element
(section 4.6).
- Single Precision Floating Point If
the value of the datatype attribute specifies datatype "float",
the data in the BINARY serialization shall consist of
ANSI/IEEE-754 32-bit floating point numbers in big-endian order.
All IEEE special values are recognized. The IEEE NaN
pattern is used to represent ``null" values.
The representation of a Floating Point number in the
TABLEDATA serialization is made of an optional - or +,
followed by the ASCII representation of a positive decimal number,
and followed eventually by the ASCII letter "E" or "e"
introducing the base-10 exponent made of an optional - or +
followed by 1 or 2 digits. The number must be within the limits of the
IEEE floating-point definition (around ±3.4⋅1038; numbers with
absolute value less than about 1.4⋅10–45 are equated to zero);
the default representation of a null value is an empty cell
(see VALUES definitions above), and the special
values "+Inf", "-Inf", and "NaN" are accepted.
- Double Precision Floating Point If
the value of the datatype
attribute specifies datatype "double",
the data in the BINARY serialization shall consist of ANSI/IEEE-754
64-bit double precision floating point numbers in big-endian order.
All IEEE special values are recognized. The IEEE NaN
pattern is used to represent ``null" values.
The representation of a Double number in the
TABLEDATA serialization is made of an optional - or +,
followed by the ASCII representation of a positive decimal number,
and followed eventually by the ASCII letter "E" or "e"
introducing the base-10 exponent made of an optional - or +
followed by 1 or 2 digits. The number must be within the limits of the
IEEE floating-point definition (around ±1.7⋅10308; numbers with
absolute value less than about 5⋅10–324 are equated to zero);
the default representation of a null value is an empty cell
(see VALUES definitions above), and the special
values "+Inf", "-Inf", and "NaN" are accepted.
- Single Precision Complex If the value of the datatype
attribute specifies datatype "floatComplex",
the data in the BINARY serialization shall consist of a sequence of
pairs of 32-bit single precision floating point numbers in big-endian order.
The first member of each
pair shall represent the real part of a complex number and the
second member shall represent the imaginary part of that complex
number. If either member contains a NaN,
the entire complex value is ``null".
The representation of a Floating Complex number in the
TABLEDATA serialization is made of two representations
of a Single Precision Floating Point numbers separated by at least
one blank, representing the real and imaginary part respectively;
the default representation of a null value is an empty cell
(see VALUES definitions above)
- Double Precision Complex If the
value of the datatype
attribute specifies datatype "doubleComplex",
the data in the BINARY serialization shall consist of a
sequence of pairs of 64-bit double precision floating point numbers
in big-endian order.
The first member of each pair shall represent the real part of a
complex number and the second member of the pair shall represent the
imaginary part of that complex number. If either member contains a
NaN, the entire complex
value is ``null".
The representation of a Double Complex number in the
TABLEDATA serialization is made of two representations
of a Double Precision Floating Point numbers separated by at least
one blank, representing the real and imaginary part respectively;
the default representation of a null value is an empty cell
(see VALUES definitions above)
7 A simplified view of the VOTable 1.1 Schema
The XML Schema [8] defining the VOTable document
is available from
http://vizier.u-strasbg.fr/xml/VOTable-1.1.xsd
7.1 Element Hierarchy
The illustration of the XML schema uses the following conventions:
italicized text represents optional elements;
indicates that the order of the elements is mandatory,
while the open bullet indicates that the elements may
occur in any order; the symbol marks a choice
between alternatives. The dots ⋅⋅⋅ indicate than an element
may be repeated. The underlined elements are explained
in a dedicated box.
|
| <VOTABLE> |
| \order <DESCRIPTION> |
| \order <DEFINITIONS> |
| \unorder <COOSYS>⋅⋅⋅ |
| \unorder <PARAM>⋅⋅⋅ |
| \order <INFO>⋅⋅⋅ |
| \order <RESOURCE>⋅⋅⋅ |
| </VOTABLE> |
|
| <RESOURCE> |
| \order <DESCRIPTION> |
| \order <INFO>⋅⋅⋅ |
| \order <COOSYS>⋅⋅⋅ |
| \order <PARAM>⋅⋅⋅ |
| <LINK>⋅⋅⋅ |
| \order <TABLE>⋅⋅⋅ |
| \order <RESOURCE>⋅⋅⋅ |
| </RESOURCE> |
|
| <TABLE> |
| \order <DESCRIPTION> |
| \unorder <FIELD>⋅⋅⋅ |
| \unorder <PARAM>⋅⋅⋅ |
| \unorder <GROUP>⋅⋅⋅ |
| \order <LINK>⋅⋅⋅ |
| \order <DATA> |
| </TABLE> |
|
| <DATA> |
| <TABLEDATA> |
| \order <TR>⋅⋅⋅ |
| \order <TD>⋅⋅⋅ |
| <BINARY> |
| \order <STREAM> |
| <FITS> |
| \order <STREAM> |
| </DATA> |
| | |
| <GROUP> |
| \order <DESCRIPTION> |
| \unorder <FIELD>⋅⋅⋅ |
| \unorder <PARAM>⋅⋅⋅ |
| \unorder <GROUP>⋅⋅⋅ |
| </GROUP> |
|
| <PARAM> |
| \order <DESCRIPTION> |
| \order <VALUES> |
| \order <LINK>⋅⋅⋅ |
| </PARAM> |
|
| <FIELD> |
| \order <DESCRIPTION> |
| \order <VALUES> |
| \order <LINK>⋅⋅⋅ |
| </FIELD> |
|
| <VALUES> |
| \order <MIN> |
| \order <MAX> |
| \order <OPTION>⋅⋅⋅ |
| \unorder<OPTION>⋅⋅⋅ |
| </VALUES> |
| | |
| |
|
7.2 Attribute summary
The list of the attributes is summarized in the table below;
attributes written in bold are required attributes,
while the attributes written in a fixed font are optional.
The italicized attributes are mentioned in the
Appendix, and are not part of VOTable 1.1
|
|
|
|
|
|
| | |
| |
|
|
| PARAM |
| (section~PARAM) | |
ID |
| unit |
| datatype |
| precision |
| width |
| ref |
| name |
| ucd |
| utype |
| value |
| arraysize |
|
| FIELD |
| (section~FIELD) | |
ID |
| unit |
| datatype |
| precision |
| width |
| ref |
| name |
| ucd |
| utype |
| arraysize |
| type |
|
|
|
| LINK |
| (section~LINK) | |
ID |
| content-role |
| content-type |
| title |
| value |
| href |
| gref |
| action |
|
|
8 Differences between versions 1.0 and 1.1
The differences between version 1.1 of VOTable and the preceding
version 1.0 are:
- the introduction of GROUP element (description)
- the introduction of the utype attribute in the FIELD,
PARAM and GROUP elements (description)
- generalisation of the description of a table as an unordered
mixture of FIELD, PARAM and GROUP
elements
- the INFO elements may exist in TABLE as well as
RESOURCE
- the VALUE element can have a ref attribute
- the usage and scope of the null attribute was clarified
- in the BINARY serialization, there is no requirement
of having fixed-length columns first.
|
9 References
[1] Accomazzi et. al, Describing Astronomical Catalogues and
Query Results with XML
http://vizier.u-strasbg.fr/doc/astrores.htx
[2] FITS: Flexible Image Transport
Specification, specifically the Binary Tables
Extension
http://fits.gsfc.nasa.gov/
[3] Standards for Astronomical
Catalogues: Units, CDS Strasbourg
http://vizier.u-strasbg.fr/doc/catstd-3.2.htx
See also Section 4 in Greisen and Calabretta 2002,
A&A 395, 1061; and the IAU Recommendations concerning Units
from the IAU Style Manual by G.A. Wilkins (1989)
available at
http://www.iau.org/IAU/Activities/nomenclature/units.html
[4] Unified Content
Descriptors
http://vizier.u-strasbg.fr/doc/UCD.htx (UCD1)
http://www.ivoa.net/twiki/bin/view/IVOA/IvoaUCD
[5] GLU: Générateur de Liens Uniformes, CDS
Strasbourg
http://simbad.u-strasbg.fr/glu/glu.htx
[6] ASU: Astronomical Server URL, CDS
Strasbourg
http://vizier.u-strasbg.fr/doc/asu.html
[7] XDF: Extensible Data format, ADC
http://xml.gsfc.nasa.gov/XDF/XDF_home.html
[8] XML Schema: W3C Document
http://www.w3.org/XML/Schema
Appendices
A Possible VOTable extensions
The definitions enclosed in this appendix
are not part of VOTable 1.1, but are considered as candidates
for VOTable improvements.
A.1 VOTable LINK substitutions
The LINK element in Astrores [1]
contains a mechanism for string substitution,
which is a powerful way of defining a link to external data
which adapts to each record contained in the table DATA.
When a LINK element appears within a RESOURCE or a
TABLE element,
extra functionality is implied. The href
or gref attributes may not be a simple link, but instead
a template for a link. If, in the example of
myFavouriteGalaxies, we add the link
<LINK href="http://ivoa.net/lookup?Galaxy=${Name}&RA=${RA}&DE=${DE}"/>
a substitution filter is applied in the context of a particular row.
For the first row of the table, the substitution would result in the URL
http://ivoa.net/lookup?Galaxy=N++224&RA=010.68&DE=%2b41.27
Whenever the pattern ${...}
is found in the original link, the part in the braces is compared
with the set of ID (preferably) or name
attributes of the fields of the table. If a match is found, then the
value from that field of the selected row is used in place of the
${...}. If no match is found, no substitution is made. Thus the
parser makes available to the calling application a value of the href
and gref
attributes that depends on which row of the table has been selected.
Another way to think of it is that there is not a single link
associated with the table, but rather an implicitly defined new
column of the table. This mechanism can be used to connect each row
of the table to further information resources.
The purpose of the link is defined by the content-role
attribute. The allowed values are "query"
(see query mechanism),
"hints" for information for use by the application,
and "doc" for human-readable documentation.
The column names invoked in the pattern of the href attribute
of the LINK element should exist in the document to
generate meaningful links.
In the common case where the VOTable was generated from a query
of a database and contains only some of the columns in that
database, it might be necessary to include columns additional to
those requested in order to ensure that the LINKS in the VOTable
are operational.
Such a FIELD included ``by necessity'' is marked with
by the attribute type="hidden". The primary key of
a relational table is a typical example of a FIELD
which would carry the type="hidden" attribute.
A.2 VOTable Query Extension
The metadata part included in a RESOURCE contains
all the details necessary to create a form for querying
the resource. The addition of a link having the action
attribute can turn VOTable into a powerful query interface.
In Astrores [1], the details on the input parameters available in
queries are described by the
PARAM and FIELD elements, and the syntax used
to generate the actual query is described in the ASU [6] procotol:
the FIELD or PARAM elements are
paired in the form name=value,
where name is the contents of the
name attribute of a FIELD or PARAM,
and value represents a constraint
written with the ASU conventions (e.g. "<8"
or "12.0..12.5"
which denotes a range of values).
Such pairs are appended to the
action specified in the LINK
element contained in the RESOURCE,
separated by the ampersand (&) symbol –
in a way quite similar to the HTML syntax used to
describe a FORM.
A special type="no_query" attribute of the
PARAM or FIELD elements marks the fields
which are not part of the form, i.e. are ignored
in the collection of name=value pairs.
The following is an example of a transformation of the VOTable
in the example into a form interface:
<?xml version="1.0"?>
<VOTABLE version="1.1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://vizier.u-strasbg.fr/xml/VOTable.xsd">
<DEFINITIONS>
<COOSYS ID="J2000" equinox="2000." epoch="2000." system="eq_FK5"/>
</DEFINITIONS>
<RESOURCE name="myFavouriteGalaxies" type="meta">
<PARAM name="-out.max" ucd="NUMBER" datatype="int" value="50">
<DESCRIPTION>Maximal number of records to retrieve</DESCRIPTION>
</PARAM>
<LINK content-role="query" action="myQuery?-source=myGalaxies&" />
<TABLE name="results">
<DESCRIPTION>Velocities and Distance estimations</DESCRIPTION>
<PARAM name="Epoch" datatype="float" ucd="TIME_EPOCH"
value="2003.875/">
<FIELD name="RA" ID="col1" ucd="POS_EQ_RA_MAIN" ref="J2000" datatype="float"
width="6" precision="2" unit="deg"/>
<FIELD name="Dec" ID="col2" "POS_EQ_DEC_MAIN" ref="J2000" datatype="float"
width="6" precision="2" unit="deg"/>
<FIELD name="Name" ID="col3" ucd="ID_MAIN" datatype="char" arraysize="8*"/>
<FIELD name="RVel" ID="col4" ucd="VELOC_HC" datatype="int"
width="5" unit="km/s"/>
<FIELD name="e_RVel" ID="col5" ucd="ERROR" datatype="int"
width="3" unit="km/s"/>
<FIELD name="R" ID="col6" ucd="PHYS_DISTANCE_TRUE" datatype="float"
width="4" precision="1" unit="Mpc">
<DESCRIPTION>Distance of Galaxy, assuming H=75km/s/Mpc</DESCRIPTION>
</FIELD>
</TABLE>
</RESOURCE>
</VOTABLE>
|
Note that the RESOURCE displaying the parameters accessible
for a query has the type="meta"
attribute; it is also assumed that only one LINK
having the content-role="query"
attribute together with an action
attribute exists within the current RESOURCE.
The PARAM with name="-out.max" has been added in this
example to control the size of the result.
A valid query generated by this VOTable could be:
myQuery?-source=myGalaxies&-out.max=50&R=10..100
A.3 Arrays of variable-length strings
Following the FITS conventions, strings are defined as arrays of
characters. This definition raises problems for the definition
of arrays of strings, which have then to be defined as 2D-arrays
of characters – but in this case only the slowest-varying dimension
(i.e. the number of strings) can be variable. This limitation becomes severe when a table column contains a set
of remarks, each being made of a variable number of characters as it
occurs in practice.
FITS invented the Substring Array convention (defined in an appendix,
i.e. not officially approved) which defines a separator character
used to denote the end of a string and the beginning of the next one.
In this convention (rA:SSTRw/ccc) the total size of the character
array is specified by r, w defines the maximum length of one string,
and ccc defines the separator character as its ASCII equivalent value.
The possible values for the separator includes the space and any printable
character, but excludes the control characters.
Such arrays of variable-length strings are frequently useful e.g.
to enumerate a list of properties of an observed source, each property being
represented by a variable-length string.
A convention similar to the FITS one could be introduced in
VOTable in the arraysize
attribute, using the s followed by the separator character;
an example can be arraysize="100s,"
indicating a string made of up to 100 characters, where the comma
is used to separate the elements of the array.
A.4 FIELDs as data pointers
Rather than requiring that all data described in the set of FIELDs
are contained in a single stream which follows the metadata part,
it would be possible to let the FIELD act as
a pointer to the actual data, either in the form of a URI or of
a reference to a component of a multipart document.
Each component of the data described by a FIELD may effectively
have different requirements: while text data or small lists of numbers
are quite efficiently represented in pure XML, long lists like spectra
or images generate poor performances if these are converted to XML.
The method available to gain efficiency is to use a
binary representation of the whole data stream by means of the
STREAM element – at the price of delivering data in a totally non-human
readable format.
The following options would allow more flexibility in the way the
various FIELDs can be accessed:
- a FIELD can be declared as being a pointer
with the addition of a type="location" value,
meaning that the field contains a way to access the data,
and not the actual data;
- a FIELD can contain a LINK element marked
type="location" which contains in its
href attribute the partial URI to which the contents
of the column cell is appended in order to generate a
fully qualified URI.
Note that the LINK is not required – a FIELD declared
with type="location" and containing no LINK element
is assumed to contain URIs.
An example of a table describing a set of spectra could look like the following:
<TABLE name="SpectroLog">
<FIELD name="Target" ucd="ID_TARGET" datatype="char" arraysize="30*"/>
<FIELD name="Instr" ucd="INST_SETUP" datatype="char" arraysize="5*"/>
<FIELD name="Dur" ucd="TIME_EXPTIME" datatype="int" width="5" unit="s"/>
<FIELD name="Spectrum" ucd="DATA_LINK" datatype="float" arraysize="*"
unit="mW/m2/nm" type="location">
<DESCRIPTION>Spectrum absolutely calibrated</DESCRIPTION>
<LINK type="location"
href="http://ivoa.spectr/server?obsno="/>
</FIELD>
<DATA><TABLEDATA>
<TR><TD>NGC6543</TD><TD>SWS06</TD><TD>2028</TD><TD>01301903</TD></TR>
<TR><TD>NGC6543</TD><TD>SWS07</TD><TD>2544</TD><TD>01302004</TD></TR>
</TABLEDATA></DATA>
</TABLE>
|
The reading program has therefore to retrieve the data
for this first row by resolving the URI
http://ivoa.spectr/server?obsno=01301903
The same method could also be immediately applicable to Content-IDs
which designate elements of a multipart message, using the protocol
prefix cid: [RFC2111]
Note that the VOTable LINK substitution proposed in
Appendix A fills a similar functionality:
generate a pointer which can incorporate in its address components
from the DATA part for the VOTable.
A.5 Encoding individual table cells
Accessing binary data improves quite significantly the efficiency
both in storage and CPU usage, especially when one compares with the
XML-encoded data stream. But binary data cannot be included in the
same stream as the metadata description, unless a dedicated coding
filter is applied which converts the binary data into an ASCII representation.
The base64 is the most used filter which does this conversion, where
3 bytes of data are coded as 4 ASCII characters, which implies an overhead of
33% in storage, and some (small) computing time necessary for the reverse
transformation.
In order to keep the full VOTable document in a unique stream,
VOTable 1.0 introduced the encoding attribute in the
STREAM element, meaning that the data, stored as binary records,
are converted into some ASCII representation compatible with the
XML definitions. One drawback of this method is that the entire data
contents become non human-readable.
The addition of the encoding attribute in the TD element
allows the data server to decide, at the cell level, whether it is more
efficient to distribute the data as binary-encoded or as edited
values. The result may look like the following:
<TABLE name="SpectroLog">
<FIELD name="Target" ucd="ID_TARGET" datatype="char" arraysize="30*"/>
<FIELD name="Instr" ucd="INST_SETUP" datatype="char" arraysize="5*"/>
<FIELD name="Dur" ucd="TIME_EXPTIME" datatype="int" width="5" unit="s"/>
<FIELD name="Spectrum" ucd="SPECT_FLUX_VALUE" datatype="float" arraysize="*"
unit="mW/m2/nm" precision="E3"/>
<DATA><TABLEDATA>
<TR><TD>NGC6543</TD><TD>SWS06</TD><TD>2028</TD><TD encoding="base64">
QJKPXECHvndAgMScQHul40CSLQ5ArocrQLxiTkC3XClAq0OWQKQIMUCblYFAh753QGij10BT
Em9ARKwIQExqf0BqbphAieuFQJS0OUCJWBBAhcrBQJMzM0CmRaJAuRaHQLWZmkCyhytAunbJ
QLN87kC26XlA1KwIQOu+d0DsWh1A5an8QN0m6UDOVgRAxO2RQM9Lx0Din75A3o9cQMPfO0C/
dLxAvUeuQKN87kCXQ5ZAjFodQH0vG0B/jVBAgaHLQI7Ag0CiyLRAqBBiQLaXjUDYcrBA8p++
QPcKPUDg7ZFAwcKPQLafvkDDlYFA1T99QM2BBkCs3S9AjLxqQISDEkCO6XlAmlYEQKibpkC5
wo9AvKPXQLGBBkCs9cNAuGp/QL0euEC4crBAuR64QL6PXEDOTdNA2987QN9T+EDoMSdA8mZm
QOZumEDDZFpAmmZmQGlYEEBa4UhAivGqQLel40Dgan9A4WBCQLNcKUCIKPZAk1P4QNWRaEEP
kWhBKaHLQTkOVkFEan9BUWBCQVyfvg==
</TD></TR>
</TABLEDATA></DATA>
</TABLE>
|
When decoded, the contents of the last column is the binary representation
of the spectrum, as defined in the BINARY serialization;
no length prefix is required here, the total length of the array being
implicitely defined by the length of the encoded text.
A.6 Additional TABLE attributes
The GROUP introduced in version 1.1 can be qualified
by ucd and utype attributes. These attributes
could similarly bring useful additional metadata to qualify the
TABLE structure.
A.7 A new XMLDATA serialization
In order to facilitate the usage of the standard XML query tools
which are easier to handle when each parameter has its individual
tag, the XMLDATA serialization introduces the designation of
each FIELD by a dedicated tag. An example could look like
the following:
<TABLE name="Messier">
<FIELD name="Number" ID="M" ucd="ID_NUMBER" datatype="int" >
<DESCRIPTION>Messier Number</DESCRIPTION>
</FIELD>
<FIELD name="R.A.2000" ID="RA" ucd="POS_EQ_RA_MAIN" ref="J2000" unit="deg"
datatype="float" width="5" precision="1" />
<FIELD name="Dec.2000" ID="DE" ucd="POS_EQ_DEC_MAIN" ref="J2000" unit="deg"
datatype="float" width="5" precision="1" />
<FIELD name="Name" ID="N" ucd="ID_ALTERNATIVE" datatype="char" arraysize="*">
<DESCRIPTION>Common name used to designate the Messier object</DESCRIPTION>
</FIELD>
<FIELD ID="T" name="Classification" datatype="char" arraysize="10*"
ucd="CLASS_OBJECT">
<DESCRIPTION>Classification (galaxy, glubular cluster, etc)</DESCRIPTION>
</FIELD>
<DATA><XMLDATA>
<TR>
<M>3</M>
<RA>205.5</RA>
<DE>+28.4</DE>
<N/>
<T>Globular Cluster</T>
</TR>
<TR>
<M>31</M>
<RA>010.7</RA>
<DE>+41.3</DE>
<N>Andromeda Galaxy</N>
<T>Galaxy</T>
</TR>
</XMLDATA></DATA>
</TABLE>
|
The full document would need an XML-Schema definition of the tags
M, RA, DE, N and T; these being
derived directly from the ID attribute of the FIELD
element, their definition can be generated automatically from the set of
FIELD definitions.